Transformer architecture is one of those ideas in AI that quietly changed everything. It didn't arrive with a big splash outside academic circles, but once it took hold, it became the foundation of tools many people now use daily—without knowing it. From language translation to voice assistants, search engines, and advanced chatbots, transformers have made machines much better at understanding language.
What makes them stand out isn't just accuracy but the way they process information: not one word at a time, but all at once. That shift helped AI systems understand meaning, context, and subtle nuance in ways older models couldn't.
The Basics of Transformer Architecture
Transformers are a type of neural network designed for handling sequences, such as sentences. Unlike older models, such as RNNs or LSTMs, transformers examine the full input all at once, which helps preserve context and meaning. This design makes it possible for models to deal with long sentences without forgetting earlier words.
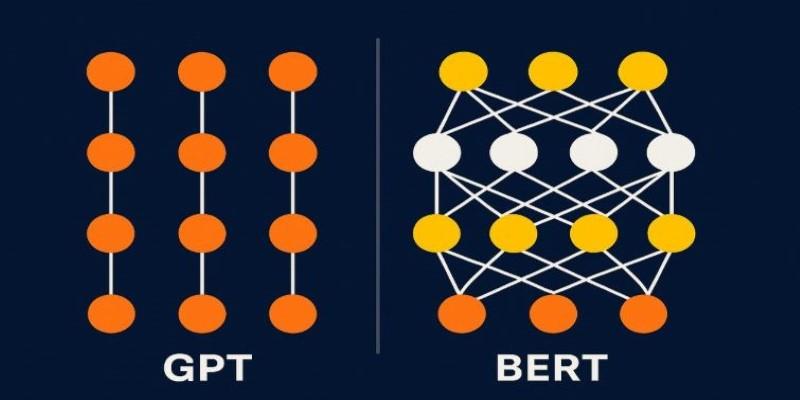
Each transformer has two parts: the encoder and the decoder. The encoder processes the input and creates a representation of it. The decoder uses that to produce the output, such as a translated sentence or generated text. Some systems only need the encoder (like BERT), while others only use the decoder (like GPT).
What sets transformers apart is how they use self-attention, a method for understanding how words relate to each other. If you’re reading, “The book that John read was interesting,” the word “book” connects closely with “interesting.” Transformers can pick up on these kinds of relationships, even when words are far apart.
Self-Attention and How It Helps?
Self-attention is how the model decides which words are most relevant to others in the same sentence. It assigns scores to word pairs, figuring out how much attention each one deserves. These scores are used to weigh the words when creating a final representation of the sentence.
Each word is turned into a numerical vector. The model compares every word to every other word to calculate relationships. The stronger the connection, the more weight that pair carries in the final understanding.
Transformers don’t just do this once—they stack layers of self-attention, refining results each time. Inside each layer are multiple attention heads. One might focus on structure, another on meaning. This gives the model a broader sense of language and better results in tasks like summarization or translation.
Since transformers look at all the input at once, they work well with longer text. This global perspective is one reason they’ve been so successful.
Training, Tokens, and Why It Works So Well?
Transformers learn by being trained on huge collections of text. They don’t "understand" language like humans but find patterns by predicting what comes next. The text is split into smaller parts called tokens. These might be whole words or bits of words, depending on the tokenizer used.
Training involves showing the model a sentence and asking it to guess the next token, then correcting it. Over time, the model gets better at recognizing which word sequences make sense. Because of self-attention, it can take all words in a sentence into account—not just nearby ones.
To keep track of word order, transformers use positional encoding. Since self-attention treats all words equally in space, the model needs a way to know where each word is in the sentence. Positional encoding solves this by adding unique signals for each word's position.
Encoders and decoders in transformers are built from repeating blocks. Each block includes a self-attention mechanism and a feed-forward layer. These blocks are stacked, sometimes in the dozens, depending on how large the model is.
Some well-known transformer-based models include BERT, GPT, and T5. Each of these uses the architecture slightly differently. GPT focuses on next-word prediction using only a decoder. BERT, which uses only the encoder, is built for tasks like classification and question answering.
Applications and Why Transformers Took Over?
Transformers are used in many everyday tools. You’ll find them behind chatbots, translation tools, grammar checkers, and smart search systems. They help models understand tone, meaning, and even sarcasm. This is thanks to how self-attention helps track relationships across full sentences.
In translation, transformers have replaced older models because they offer better accuracy and fluidity. In search engines, they help return results that are more relevant to what someone meant, not just what they typed. In writing tools, they can help suggest entire sentences or fix grammar with impressive accuracy.
Their ability to scale well on modern hardware has also made them attractive. Because they can be trained in parallel across multiple processors, they handle huge datasets quickly. This is how large models like GPT-3 and Claude became possible.
Another reason they’re widely used is transfer learning. Once a transformer is trained on a large, general dataset, it can be fine-tuned for specific tasks using far less data. This reduces the time and resources needed to train specialized models and makes it easier to adapt to new problems.
Transformers are not without challenges. They require significant computing power, can be expensive to train, and need careful attention to avoid producing biased or nonsensical results. Still, their performance often outweighs these concerns.
Conclusion
Transformer architecture has reshaped how machines process language. By allowing models to consider entire inputs at once—and by using self-attention to understand complex word relationships—transformers made natural language processing far more effective. This architecture forms the base of many AI tools used today, from chat apps to document editors. While they demand high computing resources and careful tuning, their results have pushed language models far beyond what older methods could manage. As AI continues to evolve, transformers are likely to remain central—not just for language, but for images, audio, and more