As companies and scientists strive for better AI, adjusting large language models has become a hot issue. Base models are strong, but they sometimes lack expertise in specific areas or the ability to perform specialized tasks. That's when fine-tuning helps developers tailor models to specific requirements. LoRA is among the most discussed methods.
It soon became well-known for enabling smaller teams to make fine-tuning more affordable, faster, and easily available. With new techniques being developed, however, many are questioning whether one should still rely on LoRA now. The focus of this guide is on what LoRA is, why it has gained such widespread recognition, its current limitations, and alternative options. You will also gain useful best practices to help you make informed decisions about your tweaking choices.

What is LoRA in LLM Fine-Tuning?
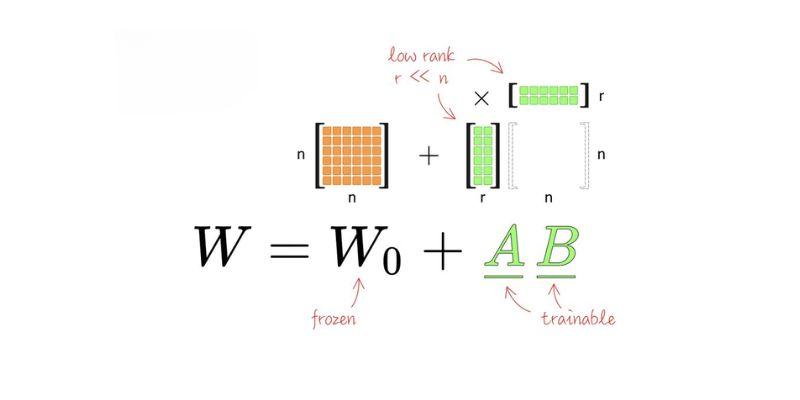
Created for large language models, LoRA—short for Low-Rank Adaptation—is a parameter-efficient approach to fine-tuning large language models. Conventional fine-tuning requires enormous computer power, as it involves training billions of parameters. LoRA addresses this issue by freezing most of the model and only training tiny low-rank matrices inserted into certain layers. These additional matrices record task-specific modifications without affecting the overall model. Once they've been trained, the LoRA modules can be combined back into the base model or left separate, allowing them to be used whenever needed.
It makes it feasible to fine-tune extremely large models on small hardware, thereby reducing costs, accelerating training, and minimizing memory usage. LoRA enables developers to adjust a small number of parameters, rather than retraining a 175-billion-parameter model, for instance. It enables people, companies, and research teams with few resources to adjust their projects. LoRA is most effective for narrow, task-specific customization, such as turning a general model into a legal assistant or healthcare support tool.

Why Did LoRA Become So Popular?
LoRA quickly gained recognition because it struck the right balance between efficiency and usability. Unlike older methods, it did not require full retraining or massive infrastructure, which often placed fine-tuning out of reach for smaller organizations. Instead, LoRA focused on updating only specific low-rank components, which enabled fine-tuning to run faster and more cost-effectively. This approach proved appealing to both academic researchers and industry developers who needed reliable customization without huge costs.
Its popularity also came from its ease of integration with existing frameworks. Many open-source libraries rapidly added support, so developers could experiment without reinventing workflows. The ability to swap adapters for different use cases further boosted adoption, since one model could serve multiple specialized tasks. By simplifying development, lowering hardware barriers, and encouraging community experimentation, LoRA built momentum quickly. It transformed fine-tuning from a specialized process reserved for top labs into something accessible and practical across many domains.
The Current Limitations of LoRA
LoRA is not the ideal response, even with its advantages. It shines in focused adaptations but falls short when assignments require extensive modifications to model behavior. LoRA may lack the capacity to capture the required complexity if you wish to modify a model for sophisticated reasoning or a very specific field. This constraint results from LoRA's updates of only tiny matrices while keeping most of the parameters static. Although LoRA is less expensive than complete fine-tuning, it still requires a significant amount of GPU capability for extremely large models.
Costs can pile up at scale, particularly if several adapters are trained. Deployment also poses problems since not all production settings easily enable loading LoRA weights, therefore adding integration overhead. Moreover, stacked adapters may lower efficiency and make maintenance more difficult. These restrictions make LoRA most suitable for small projects rather than large, field-wide modifications. That's why scientists are seeking alternative solutions to address these issues.
Alternatives Emerging Beyond LoRA
New techniques are developed as the area advances to either rival or surpass LoRA's scope. QLoRA, which combines LoRA with quantization to significantly reduce memory consumption, is a top choice among other possibilities. It allows one to tweak massive models on a single GPU without compromising speed. Prefix-tuning and adapter-tuning, two alternative parameter-efficient techniques, add modest task-specific elements into the model instead of retraining all the parameters. Depending on the task, these approaches occasionally surpass LoRA.
Another significant innovation is RAG. RAG links LLMs with external knowledge bases rather than retraining them, allowing them to access current information instantly. Rising in popularity as well is instruction-tuning using varied task datasets. It focuses on training models to follow human-like instructions across various fields, often with superior generalization compared to LoRA adaptors. Taken together, these solutions demonstrate that LoRA is still vital, but it is no longer the sole effective approach. Based on particular objectives and available resources, the fine-tuning environment now presents several options.
Best Practices for Fine-Tuning Today
Selecting the best fine-tuning approach requires careful consideration, given the numerous possibilities. The first step is to define the task. LoRA remains a viable option for those seeking limited, task-specific adaptation. For more general improvements in several areas, either instruction-tuning or RAG could be more effective. Still another consideration is efficiency. For large models, even LoRA can be challenging; therefore, pairing it with quantization techniques, such as QLoRA, will help lower expenses and memory usage.
Modularity is also helpful. Training multiple small adapters for different fields provides flexibility, making updates and deployments easier. Before deciding on one strategy, benchmark testing is absolutely vital. Comparing LoRA with prefix-tuning, adapter-tuning, or full fine-tuning helps you to pick the most efficient technique. Staying up to date is ultimately essential as methods change fast. Scientists routinely bring up fresh ideas; open-source initiatives usually lead the way. Following these guidelines enables companies to maximize their resources and produce excellent fine-tuning results.
Conclusion
For large language models, LoRA has been instrumental in enabling affordable, quick, and easily accessible fine-tuning. Smaller teams and companies were able to adapt to artificial intelligence without needing huge resources. But it is not the ideal fix for every circumstance. Alternatives like QLoRA, adapter tuning, and RAG offer new opportunities as model size increases and jobs become more complex. The best approach depends on the degree of customization required, available resources, and objectives. While LoRA is still useful, it is currently just one among many good choices that influence the direction of fine-tuning.