Image segmentation has seen quite the upgrade in recent years, especially with the rise of what’s now being called universal segmentation. Instead of building separate models for different segmentation tasks—like semantic, panoptic, and instance—researchers are designing a single, catch-all framework that can take on everything. That’s where models like Mask2Former and OneFormer come into play. These aren’t just incremental upgrades. They mark a shift in how segmentation is approached altogether.
So, what’s the story behind these two? How do they handle so many tasks without collapsing under complexity? Let’s walk through what makes each of them tick, how they’re different, and why they’re such a big deal in the segmentation world.
Mask2Former: The Idea Behind the Mask
When it first arrived, Mask2Former felt like someone cleaned up a messy desk and left only what mattered. It ditched the heavy reliance on pixel-level classification that earlier models leaned on and instead introduced something smarter: masked attention.
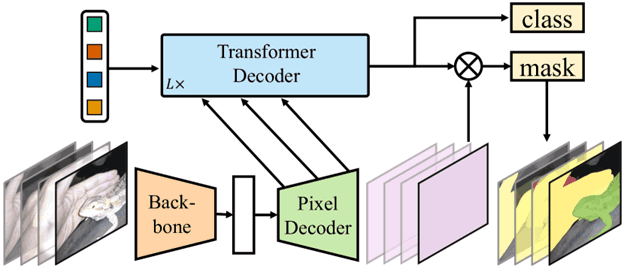
The Core of It
At its center, Mask2Former takes an image, extracts features using a CNN or Vision Transformer backbone, and then passes those features through a series of transformer decoder layers. What’s different here is how these decoders work.
Rather than looking at every pixel individually, the model creates queries—learned embeddings that try to predict masks directly. These queries interact with the image features through cross-attention. That’s how the model learns what each segment should look like. And instead of one-hot class labels, it focuses on predicting full masks.
What Makes It Work?
Masked Attention: Instead of forcing the model to consider the whole image at once, Mask2Former narrows attention only to the regions where it thinks something interesting is happening.
Multi-scale Features: It uses feature maps from different layers of the backbone, helping it recognize both small and large objects without losing detail.
Task Flexibility: You can plug in a different head depending on whether you want instance, semantic, or panoptic results. The underlying process stays the same.
What you get is a model that's not just efficient but surprisingly accurate across different segmentation tasks, with far fewer task-specific hacks than previous methods required.
OneFormer: Making Things Even More Unified
Now comes OneFormer, which doesn’t just aim to simplify the process—it tries to merge everything from the start. Where Mask2Former gives you flexibility through modular design, OneFormer pushes the idea further: why not let the model itself decide what kind of segmentation it’s doing?
How It Handles Everything
OneFormer’s key idea is task-aware decoding. That means it injects the task type—say, semantic vs. instance—directly into the model. This isn’t a separate head bolted on at the end. It’s baked into how the model thinks from the beginning.
It also brings in a dual-decoder structure:
Pixel Decoder: Handles the heavy lifting of understanding spatial details from the image.
Transformer Decoder: Interacts with learned queries (like Mask2Former) but uses a multi-task token to condition its behavior based on the task.
This setup means OneFormer doesn’t just switch modes at the end. It adapts internally, aligning its attention, its predictions, and its learned features with the segmentation goal—all at once.
Why It Works Better in Some Cases
No Post-Hoc Task Switching: The model knows its job from the start, which removes the need for task-specific tweaking later on.
Shared Learning: It benefits from seeing multiple segmentation tasks during training, which helps it learn more general features.
Efficiency Gains: Despite its complexity, it doesn't need to duplicate effort. That makes inference faster and memory usage lower.
The result? Fewer errors, especially in edge cases where a model might get confused between object boundaries or try to double-count instances.
How to Build a Simple Universal Segmentation Pipeline Using These Models
If you're looking to put theory into practice, here's a straightforward way to get started using either Mask2Former or OneFormer.
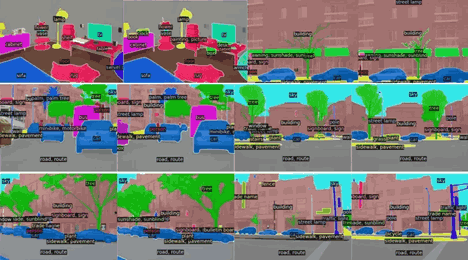
Step 1: Choose Your Backbone
Both models support a range of visual backbones—ResNet, Swin Transformer, and others. Pick one depending on your compute budget. Swin offers more performance, but ResNet is still good for prototyping.
Step 2: Decide Your Task Types
Universal doesn’t mean you have to use every task. You can start with semantic segmentation alone and add others as needed. Just ensure your dataset supports the task types you want.
Step 3: Set Up Your Environment
Clone the official repository or use Hugging Face’s pre-trained implementations. Make sure you install dependencies like PyTorch, Detectron2 (for Mask2Former), or MMSegmentation (for OneFormer).
Step 4: Load and Preprocess Data
Prepare your dataset in COCO-style or ADE20K format. These formats are widely supported and work out-of-the-box with most segmentation libraries.
Step 5: Train the Model
Fine-tune the model on your custom dataset. Most pre-trained weights are trained on COCO or ADE20K, so they transfer well. Start with a smaller learning rate and short training cycle, then scale up as needed.
Step 6: Inference and Visualization
After training, run predictions on new images. Visualize the outputs to ensure masks align well with actual object boundaries. If you're using OneFormer, you'll notice it auto-adjusts segmentation based on the task token you supply.
Final Thoughts
Universal segmentation isn’t a buzzword—it’s a direction that’s catching on fast because of how practical it is. Mask2Former cleaned up the segmentation process with masked attention and modularity. OneFormer took it a step further by injecting task awareness into the core model logic.
If you’re working in computer vision and still juggling multiple models for different segmentation needs, it might be time to simplify. These tools are already tested at scale, open-source, and surprisingly approachable once you set things up. So, whether you're tagging road signs, parsing MRI scans, or just trying to find cats in photos, there's a good chance one of these models can do it all.