The revolution of AI is made by Large Language Models (LLMs), but they may require enormous computation resources. Introduce 2-bit LLMs - very efficient but historically the less accurate. This is conquerable with EoRA (Ensemble of Ranks and Adapters ) strategies, which improve specificity without damaging accuracy. The given commercialization allows commodity-coded ultra-compressed models to become practical and useful in the real-world setting and help organizations with limited resources to implement the advanced AI in an efficient and reliable way.
Understanding 2-Bit LLMs and Their Limitations

Legacy LLMs work with 16 bit or 32-bit accuracy, and can store immense amounts of data in their parameters. The only four values represented in each parameter when reduced to 2-bit precision instead of thousands. Such a monumental loss of the ability to represent means information loss is inevitable.
Most issues of 2-bit LLMs are:
- Accuracy Degradation: The most obvious issue is the significant drop in model performance across various tasks. Complex reasoning, nuanced language understanding, and contextual awareness often suffer substantially.
- Knowledge Compression Loss: Important factual information and learned patterns get lost during the quantization process, leading to gaps in the model's knowledge base.
- Instability in Outputs: 2-bit models tend to produce less consistent results, with higher variance in their responses to similar inputs.
Despite these challenges, the benefits of 2-bit LLMs remain compelling. With a memory size roughly 8 times that of their 16-bit counterparts, these 32-bit devices can be used for inference even through adverse channel connections, in power-restricted platforms, and in dispersed devices.
What Are EoRA Strategies?
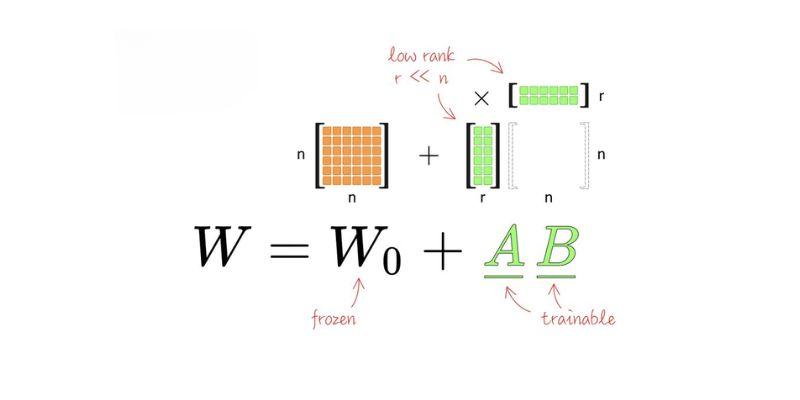
Ensemble of Ranks and Adapters (EoRA) is an advanced performance improvement strategy in 2-bit LLM that enables higher-performance without incurring much deeper computational costs. This is a cross between two potent methodologies a low-rank adaptation methodology and an ensemble methodology.
The fundamental idea of EoRA is to derive a number of specialised adapter modules that cooperate to restore the lost information of the 2-bit quantisation step. As opposed to the attempt to make one forced compressed model perform all functions properly, EoRA allocates the cognitive burden among multiple lightweight units.
Low-Rank Adaptation Component:
EoRA implies the use of low-rank matrices to convert and preserve essential information patterns that would have been lost in the process otherwise through quantization. The adapters are aimed at preserving the key feature relationships in the model that is being compressed.
Ensemble Architecture
Several adapter modules can be trained to each specialize on one aspect of the plan. Others may be concerned with preservation of factual accuracy, others are mindful of preservation of reasoning or fluency in language.
Dynamic Weighting
The system intelligently mixes outputs of various adapters depending on the exact needs of a particular input, so as to provide optimum performance with various tasks.
How EoRA Enhances 2-Bit LLM Performance
The EoRA strategies help overcome the inherent shortcomings of 2-bit LLMs in a few major ways:
Preserved Critical Information Pathways
EoRA defines the most significant information channels in the initial model and maintains them. With these essential interface links in place the system has much of the reasoning ability of the original model even when forced to extremely compress it.
The high impact parameters, which are the ones with the greatest contribution to model performance are purposefully addressed during the low-rank adapters. Such selective preservation methodology will guarantee that the information that has the greatest value is retained after the criteria of quantizing has been done.
Distributed Specialization
EoRA does not make one compressed model perform all tasks but special-purpose components of diverse functions. The first adaptor could be mathematical reasoning, the second adaptor creative writing and the third adaptor factual recall. This specialization enables every individual part to be optimized with respect to a particular area of performance.
The ensemble approach implies that when one of the adapters is having a difficult time acclimating to a certain input, there are other adapters to offset it and like this generate a belter overall performance.
Adaptive Response Generation
In an eoRA system, the response will be varied in response to input characteristics. The framework proposes the evaluation of every query and identifies the most viable cluster of adapters to generate the best result.
The adaptive mechanism enables the system to operate in the desired high performance with diverse variety of tasks; something resolveable by traditional 2-bit models only in some cases.
Real-World Applications and Benefits
The operational uses of EoRA-enhanced 2-bit LLMs span at least many areas:
Mobile and Edge Computing
The IoTs and Smartphones can now execute advanced language models without connecting to the cloud. EoRA allows mapping complex AI functions directly onto the consumer hardware, and thus provides applications such as real-time translation, voice assistants, and content generation without privacy implications posed by cloud computing.
Enterprise Cost Reduction
Companies are able to realize substantial cost savings on AI infrastructure and acquire infrastructure and services without compromising services. Models equipped with EoRA use fewer hardware resources on the GPU, need lower bandwidth and reduced storage, and this translates to significant operational savings.
Democratized AI Access
Advanced LLM capabilities are made at scale to smaller companies and research institutions without huge computational investments. Such a democratization stimulates innovation in industries where the state-of-the-art AI could not be afforded before.
Energy Efficiency
The less energy consumption is directly proportional to the reduced computational needs, which are just in line with the sustainability objectives, yet preserving the AI capacity. This effectiveness is especially valuable as the use of AI expands all over the world.
Implementation Considerations

Implementing EoRA strategies successfully means one must consider a few of the following factors:
Training Requirements
Although, EoRA helps decrease the costs of inference by far, the training process at the beginning has to use elaborate methods to optimize the ensemble of adapters. To successfully implement these systems, organizations must be experienced in quantization as well as ensemble learning.
Task-Specific Optimization
Adaptor configurations may be customized to various applications. A chat-bot will focus on conversational fluency adapters as code generation tool will focus on understanding logical reason segments.
Performance Monitoring
The EoRA systems need consistent support of performance monitoring to optimise the performance by ensuring that the adapter weighting is optimised and in case retrained of the system is needed. These systems are dynamic, and whether the deployment requires advanced strategies as opposed to the traditional models, which are not dynamic.
Conclusion
EoRA strategies are a disruptive step to efficient, accessible AI. They provide an opportunity to wider device compatibility such as 1-bit or sub-bit designs by filling the gap between full-precision and quantized models. EoRA is accessible with AI self-optimizing across different requirements due to development of automated adapter design. These methods make 2-bit LLMs useful, effective, and set a path to sustainable, real-world AI execution.